



はじめに
8月に国産LLM(大規模言語モデル)の開発を宣言してから4ヶ月が経過し、12月も新たな進捗をご報告するプレスリリースをお届けします。10月末に2つ目のプレスリリースを出しましたが、
今回の内容は、既存研究の精度にかなり近づいたものとなり、それでいて本手法が有効的なアプローチであることを裏付ける、今までで最も大事な基盤技術となります。
本リリースでは、この度の具体的な開発内容と成果についてご紹介して行きたいと思います。
※様々な指摘に関しては一番下で回答しておりますので合わせてご覧ください。
前提
本プロジェクトについて初めて読まれる方は、以下の記事をご参照ください。
※この記事や関連研究も読まずに批判、指摘している方が多くて話にならないため、これを全て読んでから批判、指摘(誹謗中傷、人格攻撃などを除く)をお願いします。


2ヶ月の成果
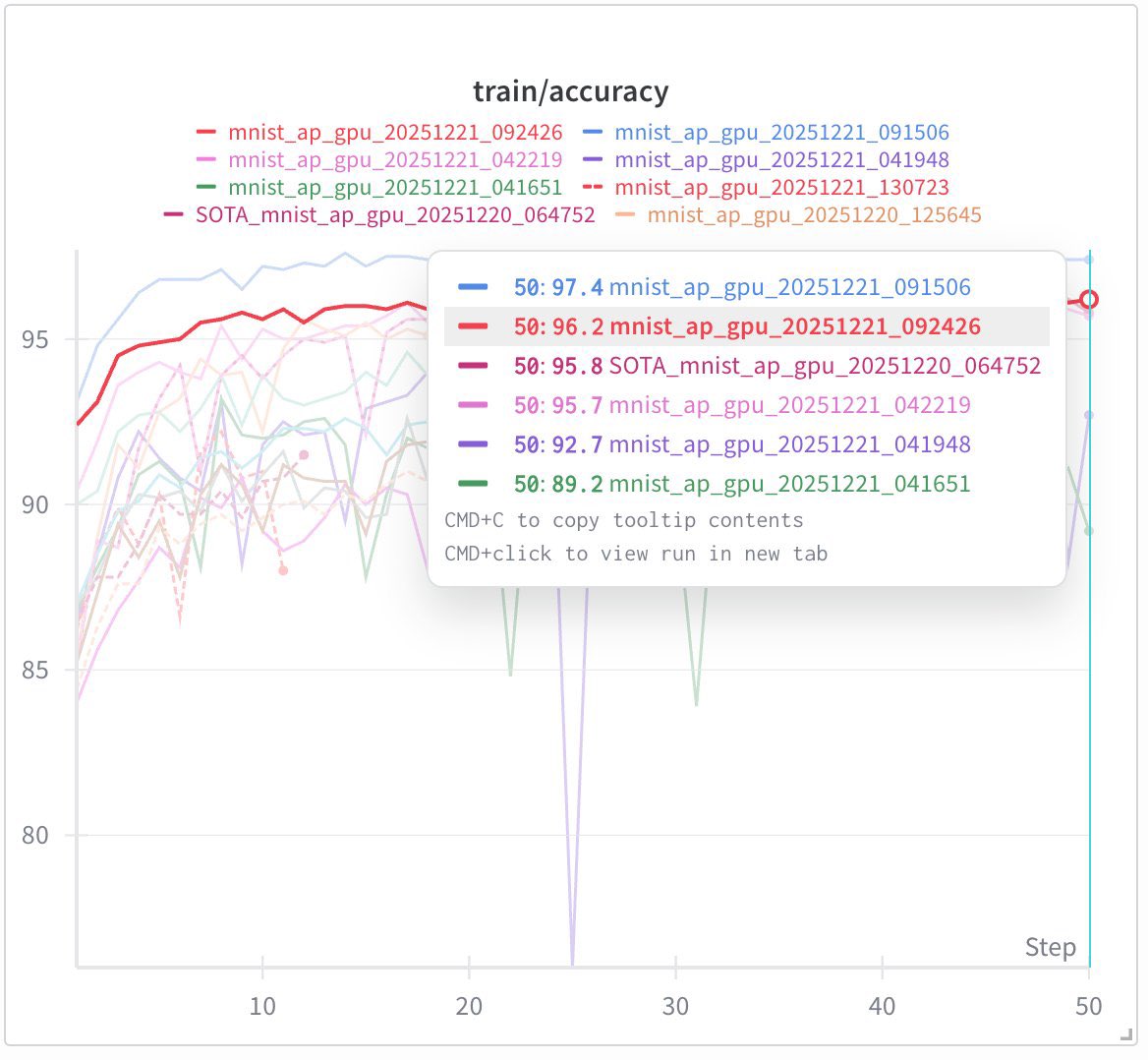
単一モデルでの精度の大幅向上(成果)
AP法により、バイナリ化設定における単一モデルの性能が大きく向上しました。評価はいずれも学習(train)ではなくテスト(test)データで実施しています。
- MNIST:96.89%
- CIFAR-10:58.2%
従来の課題
これまでバイナリ化を適用すると、精度が大きく低下することが課題でした。
- バイナリ化により、精度が約30ポイント低下するケースがあった
- MNISTでも約60%程度まで落ち込み、実運用に耐えにくかった
- さらに、出力ごとに個別モデルが必要となる構成になりやすく、結果としてパラメータ数が増大する問題があった
CIFAR-10/Fashion-MNISTへの対応拡大
AP法の検証対象として、従来のMNISTに加え、CIFAR-10を導入しました。さらに、より実用的な難易度を持つFashion-MNISTにも対応し、評価環境を拡張しています。
成果
- Fashion-MNIST:83%(精度)
従来の課題
これまで、**CIFAR-10およびFashion-MNISTを読み込むためのデータローダー(Loader)**の整備が進んでおらず、学習・評価の実験系を十分に構築できていませんでした。
クラウドGPUへの移行による実行環境の強化
AP法の開発・検証環境を、ローカル中心の運用からクラウドGPUへ移行し、実験のスループットと再現性を高めました。
成果
- RTX 5090およびNVIDIA H200クラスのGPUを活用可能な環境を整備
- 学習・評価基盤をRunPodへ移行し、検証サイクルを高速化
従来の課題
これまではM4 Max上でのローカル実行が中心で、
- 学習時間が長く、反復検証に時間を要する
- ログ取得・管理が限定的になりやすい
といった点がボトルネックとなっていました。
今後の展望
- CNN, RNN, Transformer, Attentionなどへの拡張
- 論文執筆に向けての実験と検証、コード整理
Q & A
- なんで論文出さないんですか?
- 国際学会に出すことにしました
- 特許を取ろうとしていたからです
- MNISTは簡単すぎるのでやる意味がない
- MNISTすら解けないANNの方がよっぽど問題があり、90%後半出ているAP法には可能性があると言える
- そしてMNISTだけで測るつもりは一切なかったためその後にCIFAR0-10で58%を達成。
- 私は、論理ゲート、MNIST、CIFAR…のように専門書で解説されているような順番で進めているだけ
- 5億FPSは無理じゃない?
- 1層1クロックなのでパイプライン処理では可能
- ただ、指摘されたようにデータセットを5億枚送り込む難しさは考えおらず、そこは過大評価でした
- 精度悪くない?
- BP以外のアルゴリズムは基本的に低精度である説があります
- BP以外の学習アルゴリズムであるHebb則でCIFAR-10が80%出ているのでこのAP法には意味がないのでは?
- 80%出ているものの大半はCNN使っているので、現段階で全結合しか使っていないAP法とは比較不可能です
- 例えば元ネタの論文もCNNを使っています

コメント