



はじめに
8月に国産LLM(大規模言語モデル)の開発を宣言してから2ヶ月が経過し、9月に続き、今月10月も新たな進捗をご報告するプレスリリースをお届けします。
開発着手からまだ2ヶ月という短い期間ですが、本記事のタイトルにもある通り、開発中の自作ニューロンが、限定的ながらも自然言語の生成に成功いたしました。
本リリースでは、この度の具体的な開発内容と成果についてご紹介して行きたいと思います。
前提
本プロジェクトについて初めて読まれる方は、以下の記事も併せてご参照ください。
- 国産LLMを作ることになったきっかけhttps://www.chickensblog.com/new-japan-llm
- 前回のプレスリリースhttps://www.chickensblog.com/pres-kokusann-lmm-20250923
1ヶ月の進捗
ついに自然言語生成に成功
🚀 ついに自然言語生成に成功!超高速処理を実現
今回の開発において、「い」「よ」「し」の三文字限定ではありますが、この三文字で表現できる言葉をリアルタイムに生成できるようになりました。
このモデルは、独自開発の「自作ニューロン」で動作しており、1文字あたり1クロックで出力が完了します。つまり、3文字の生成にかかる時間はわずか3クロックです。
理論上、500Mhzで動作する回路であれば、秒間5億文字を出力可能という超高速処理を実現します。
もちろん、現状は極めて小規模なモデルであり、生成できる文字も3文字に限定されるため、実用化には程遠い状態です。しかしながら、1クロックで推論が完了するというこの高速性を維持したまま文字生成が可能になったことは、今後の大規模化に向けた非常に大きな進捗であると位置づけています。
自作ニューロン用のフレームワーク開発
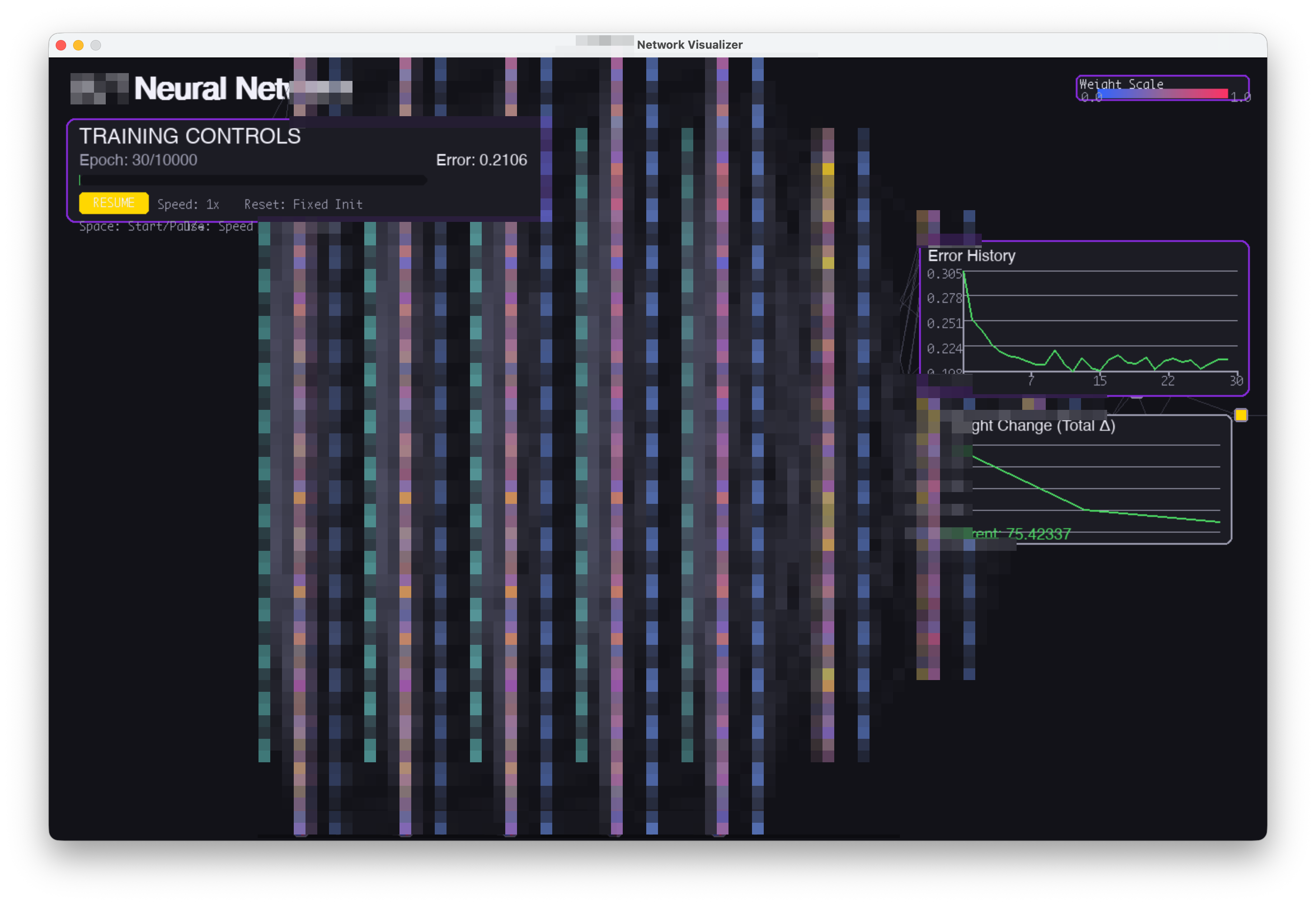
RNNの構造を可視化するビジュアライザの開発。Pygameで描画。
🔧 自作ニューロン専用のフレームワークを独自開発
AIモデルの開発においては、PyTorchやKerasなどの機械学習用フレームワークが広く利用されています。しかし、私たちの開発しているモデル、自作ニューロン、および独自学習アルゴリズムであるAP法は、既存技術とはその仕組みや構造が根本的に異なります。
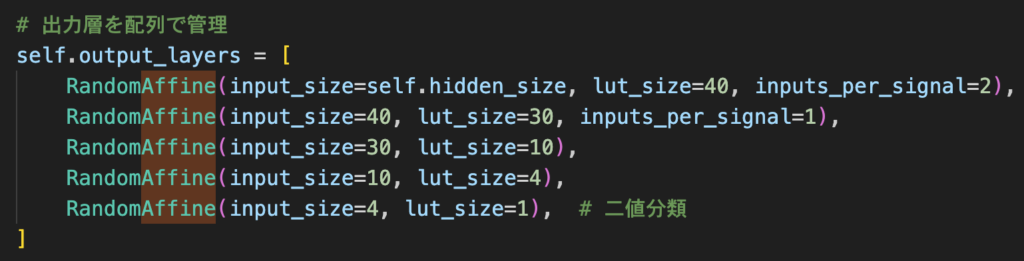
そのため、開発を効率的に進めるため、独自の機械学習フレームワークを開発しました。
このフレームワークによりAffineレイヤなどを直感的に、かつ宣言的に記述できるようになり、複雑なモデルの構築が容易になりました。
💡 新開発した学習アルゴリズムの調査と「AP法」と命名
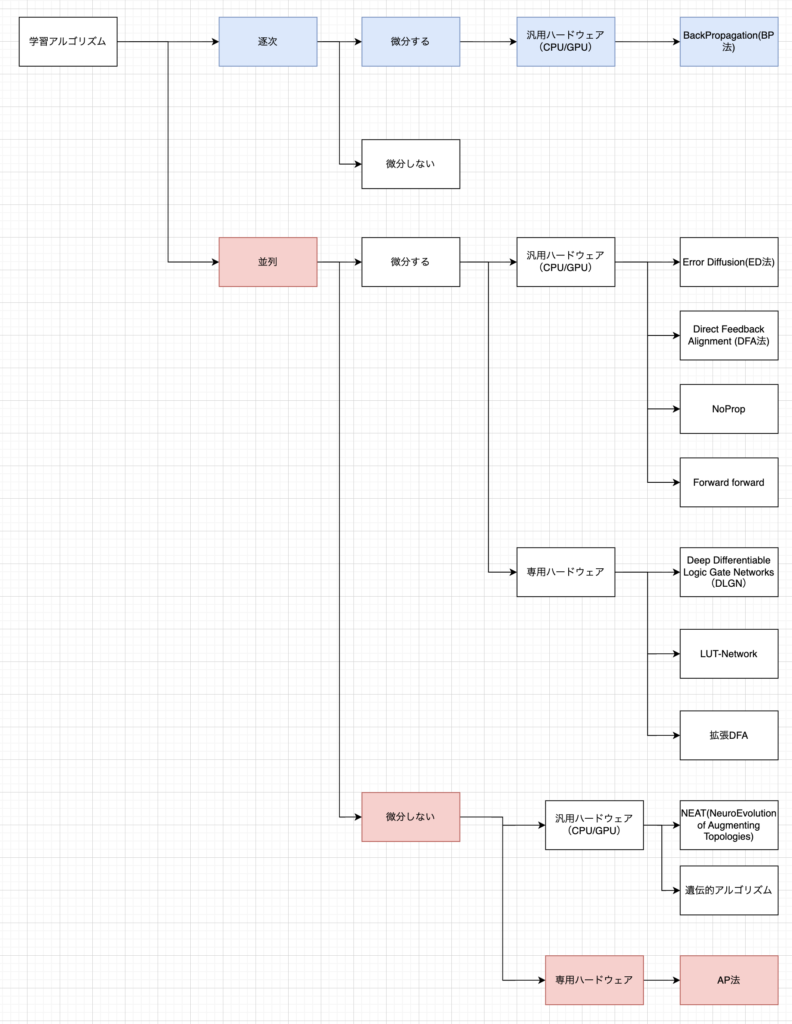
以前より、当社では誤差逆伝播法(BP法)や微分、勾配降下法を一切用いず、それでいて重みを全て並列で更新できる新しい学習アルゴリズムを開発したと発表しておりました。この度、その学習アルゴリズムの名称が決定いたしました。
その名は、「AP法(Akiho Propagation)」です。
当初はアルゴリズム自体に意味を持たせた命名を検討しておりましたが、既存の学習方法の単語から連想することが難しかったため、開発に携わる者の名前を冠する形となりました。今後の開発進捗によって名称が変わる可能性もありますが、ED法やBP法といった既存の伝播法に近い名前となり、現状は満足しております。
具体的な成果
RNNの実装と学習成功
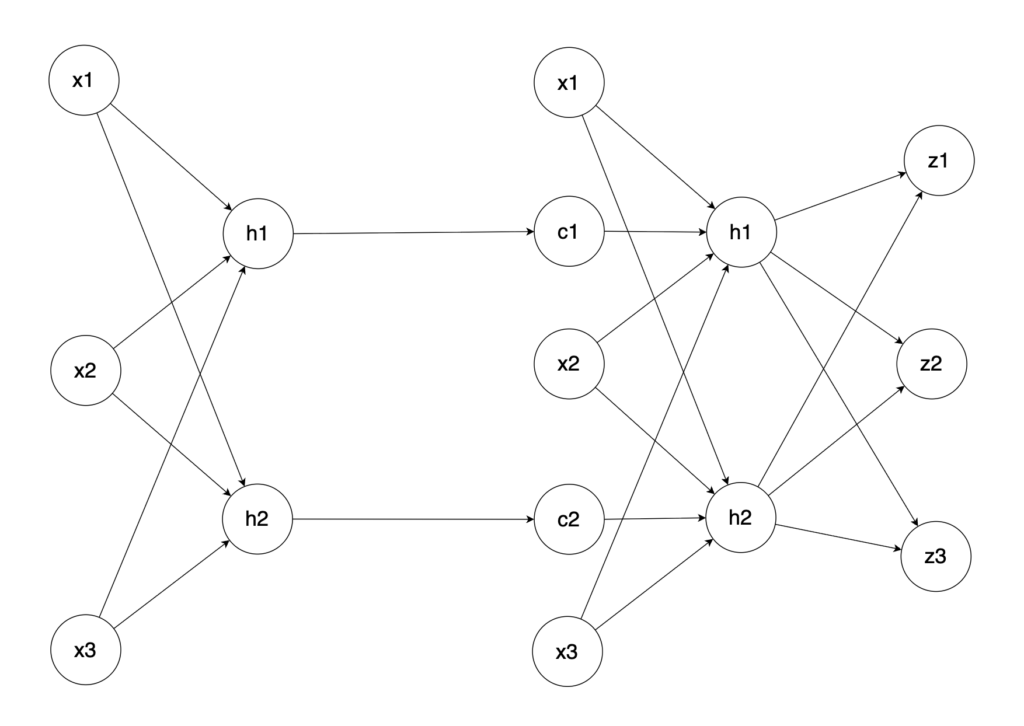
🎯 RNNの実装とAP法による学習に成功
今回開発したRNN(リカレント・ニューラル・ネットワーク)は、 画像のように非常にシンプルな構造をしています。
この構造では、中間層の出力結果(Context)が次の層の入力値に「Context」としてフィードバックされるようになっており、「い」「よ」の後に「し」が続くような、前の情報をエコー的に取り込む演算が可能です。
特筆すべきは、この最小構成のRNNが、独自開発の「AP法」で学習に成功した点です。前回のContextをもとに現在の情報を演算できるよう、AP法によって学習が完了したことは、大きな技術的ブレイクスルーとなります。

画像:t-1(前回時刻)のContextを0に固定した場合のロス率。通常であれば0.001のように0に限りなく近づくが、0.37に張り付き、一切学習しないことが見て分かる。ß
画像の説明として補足いたしますが、実際、t-1(前回時刻)の隠れ層の出力をContextとして入力に渡さない場合(即ち、0に固定した場合)には、RNNの学習が一切進まないことを確認しており、Contextの再帰的な入力がAP法による学習において不可欠であることを示しています。
🚀 今後の展望:次世代アーキテクチャへの移行
しかしながら、古典的なRNNアーキテクチャでは、その構造的限界から長期的な記憶能力(long-term dependency)や精度に限界があることを認識しています。AP法が誤差逆伝播法に依存しないため勾配消失問題の影響を受けにくいという利点はあるものの、RNN自体の構造がContextを高精度かつ長期にわたって保持することには適していません。
このため、今後はLSTM(Long Short-Term Memory)ユニットの導入、あるいはさらに進んでTransformerのようなより高度なアーキテクチャへの切り替えを視野に入れ、文章生成能力の飛躍的な向上を目指して参ります。
新しい自作ニューロンのシミュレーションエンジンおよびフレームワークの開発
新開発した学習アルゴリズムの調査&AP法と命名
⚙️ AP法による超並列学習:専用ハードウェア実装の可能性
独自に新開発した学習アルゴリズムであるAP法(Akiho Propagation)は、 微分を必要とせず、専用ハードウェア上で重みを並列に更新できるという特性を持っています。
これまでも、このアルゴリズムが専用ハードウェア向きであることは認識していましたが、さらに詳細な調査を進めた結果、AP法を汎用的なGPUやCPUを介さず、専用のハードウェア上で直接実行できる実現性の高いアーキテクチャが存在することが明らかになってきました。これは、今後の研究開発の方向性を決定づける、極めて重要な知見となります。
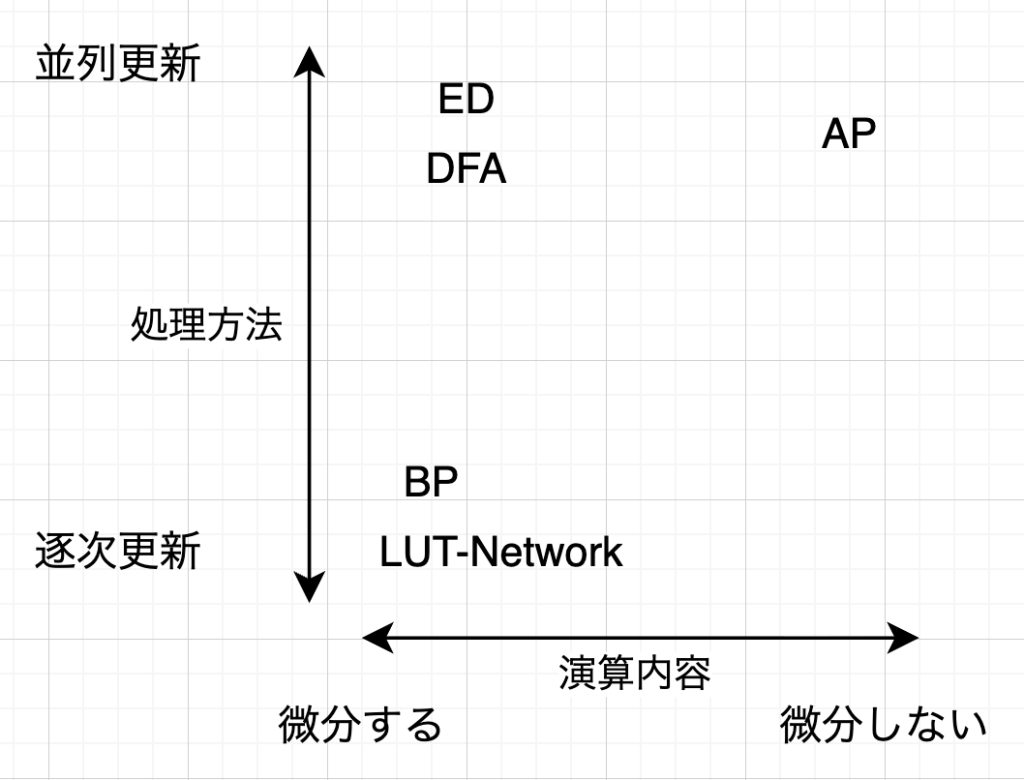
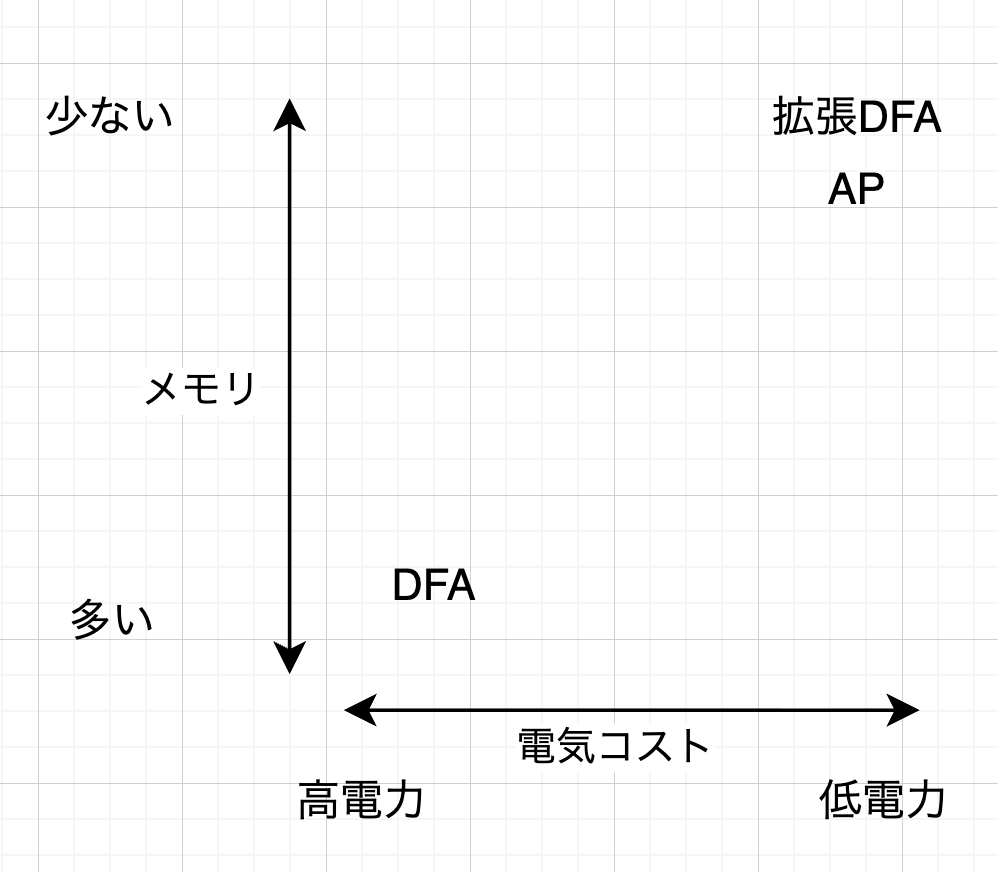
⚙️ 低電力・超高速演算を実現へ:専用ハードウェア実装に向けた進展
開発着手から約2ヶ月が経過し、当初より課題として認識していたAP法の専用ハードウェア実装について、具体的な進展がありました。
特に、Stochastic Computing(確率的計算)を用いる際の課題であった、SNG(Stochastic Number Generator)のクロック回数の多さや演算誤差といった技術的障壁に対し、克服の目処が立ちました。
この度、その成果として、汎用プロセッサ(GPU/CPU)に依存せず、専用ハードウェア上で高速かつ低電力で、推論(Inference)だけでなく学習(Training)までも実行可能な、具体的なアーキテクチャ、アルゴリズム、および初期回路図の構築が徐々に具現化してきています。
🚀 今後の展望
今回の自作ニューロンによる自然言語生成の成功と、独自学習アルゴリズム「AP法」の進展を踏まえ、今後の研究開発は以下の課題に注力し、国産LLMの実用化を目指して加速させてまいります。
- より複雑なタスクが解けるRNNの開発: 現行の最小構成RNNから一歩進め、より高度で複雑な系列タスクに対応できるRNNアーキテクチャの研究開発を進めます。
- より大規模なRNNの開発: 基礎技術の高速性を維持しつつ、モデルのパラメータ数とデータセットの規模を拡大し、大規模化(Scaling-up)を実現するための技術課題を解決します。
- LSTMの導入: 既存RNNの課題である長期依存性(Long-Term Dependency)の保持能力を克服するため、LSTM(Long Short-Term Memory)ユニットの実装を導入し、記憶力の向上を図ります。
- モデルの神経接続方法の組み合わせ問題の解明と解決: ニューラルネットワークの接続方法(アーキテクチャ)が性能に与える影響を深く研究し、最適な構造を効率的に見つけ出すための組み合わせ問題の解明と解決に取り組みます。
- AP法(Akiho Propagation)のさらなる最適化とハードウェア化: 独自開発の学習アルゴリズムであるAP法の理論的・技術的検証を継続し、低電力・超並列学習を実現する専用ハードウェアアーキテクチャの完成を目指します。
📋 まとめ
本プレスリリースでは、国産LLM開発プロジェクトが発足からわずか2ヶ月で、自作ニューロンによる自然言語の超高速生成に成功したことをご報告いたしました。
この成果は、既存技術に依存しない独自学習アルゴリズム「AP法」と、専用フレームワークの開発によって支えられています。特に、1クロックでの推論完了という高速性が、今後の大規模化における最大の強みとなります。
今後は、LSTMやTransformerといった次世代アーキテクチャの導入、そしてAP法を用いたハードウェア上での学習・推論の実現に向けて、開発を一層推進してまいります。
コメント