




アジェンダ
- はじめに
- 私について
- 開発することになった流れ
- 現在の国産LLMの課題
- どこを目指すか
- 解決方法:GPUなど使うな
- 具体的な技術
- 今後の研究開発について
- 我々からのお願い
- Q&A
はじめに
取材などのご連絡はこちらから:https://magicdelta.ai/contact/
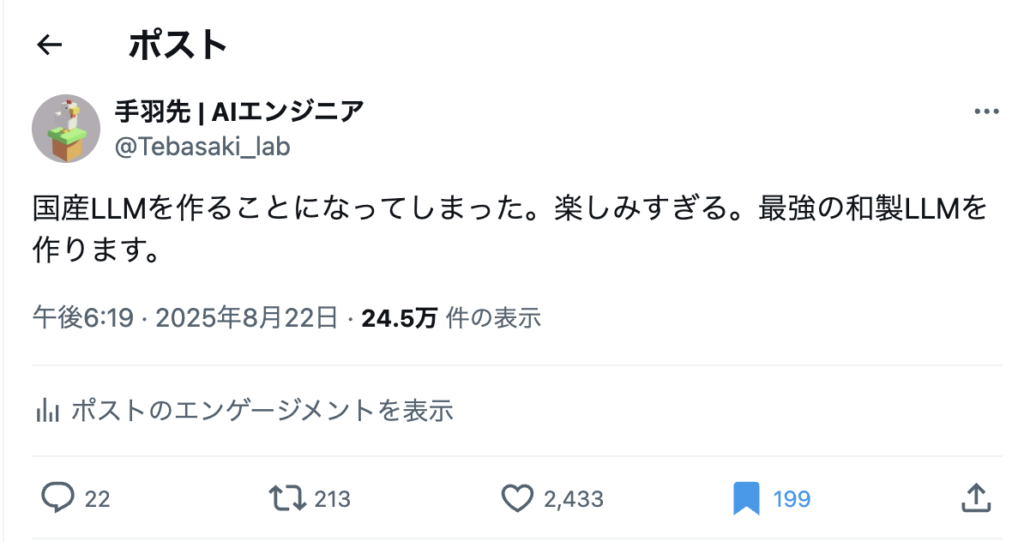
2025/08/23 9:29現在、数えきれない反応とコメント、25万件表示。数時間前まで1500フォロワーだったのが2000フォロワー超えました。
- 説明:この記事は以下の記事がバズったのでそれの補足説明やQ&Aなど書いてます
- 注意:私は学者でも政府機関関係者でもないただの変態エンジニア→国産LLMが作れるかどうかは半信半疑でエンタメとして楽しんでもらうぐらいの温度感でお願いします
- 注意:権利、プロジェクト、組織的な問題で現段階では全技術とContextは公開できません
- 公開したら米国にそりゃ真似されるよねと
- 完成したらOSSなり特許なり論文なり、完全ブラックボックスだが国益になるようなことにもっていけたらなと
- 注意:専門家じゃない人が何言ってるんだと思うかもしれないですが、あくまでエンタメで。成功したときには世界が良くなればそれでいいし、失敗すれば論文を全部公開して世界中で次の研究に繋げてもらえればと思います。
- 思想:単純に2045年までに私もAIの研究開発進めないと間に合わないので、自分がやれるところまでやってみるだけ。
- 自分で記事書いてて怪しい内容だなと思ったのですが、コードや実験内容などの進捗は Twitter で共有していくので(海外の天才たちが数千億かけて作ってるのに日本の少数部隊で挑むので進捗は数年になるかわからないが)、その時に伝われば良いかなと思います
- 注意:「(国産LLMを)誰もやらないので挑戦してみる」という発言ではなく、「(私が知ってるA, B, Cという技術で国産LLMを誰も作っていないので)誰もやらないので挑戦してみる」という発言です。
- 注意:研究者、エンジニアの方を尊敬しています→過去の研究はダメだ!とかではなく、新しいパラダイムシフトや技術をせっかくなら国産で生み出してみようよという話です
私について
取材などのご連絡はこちらから:https://magicdelta.ai/contact/


- 表向き
- 職種:Business AI Designer(AIをビジネスとして社会実装)
- AI エンジニア
- フルスタックエンジニア
- 職種:Business AI Designer(AIをビジネスとして社会実装)
- 実際
- 誤差逆伝播法に変わる学習アルゴリズム開発オタク
- 超リアルタイムコンピューティング
- なんかScratchでニューラルネットワーク作った人
- TGCA'25←SecHack365'24←ビジコン'24全国大会準優勝←福岡未踏'23 Pro ZEN大学1期生 特待生採択
- 別にAI関連の大した実績はないが、前向きに次世代技術を作り続けている人間です
2025年の6月にシアトルで機械学習のプロジェクトでGoogle社に登壇
開発することになった流れについて
- 5年ほど研究しているLLMを高速で推論、学習させる全く新しい技術の知見がある程度溜まってきて閾値を超え発火したので
- CNNやRNN, 物体検出より世界はLLMという文字を吐き出すAIがどうやら好きそうでインパクトがデカそうなので
- あるメンバーとプロジェクトで開発に着手する時期が来たため
現在の国産LLMの課題
- そもそも世界はAI戦争をGPUと札束で殴り合いをしている
- 日本がGAFAMより巨額な資金を投下するのは不可能
- 精度低い
- 遅い重い
どこを目指すか
- 10万tokens/s
- 適当に言っているだけで、実際作ってみたら5000tok/sかもしれないし1万tok/sかもしれない
- そもそもまだモデルすら完成してないので理論値も何も計算しようがないので夢は大きくしておく。小さくても意味がない
- 早いと何が良いのか?
- キャラクターとのリアルタイム会話が可能→話しかけた瞬間10万token帰ってくる
- 高速で演算するほど、性能が上がる可能性がある→普通のモデルでも、CoTすれば精度が上がる=秒間1000回CoTできたらどうなるかは考えれば分かる
- GPUでは敵わない領域の開拓→元々YOLOなどで30万FPSを目指していたのは、自動運転で使えそうだったから。しかし、LLMが10万/sいけるとなると、Cursorが0秒で動く、論文がバコバコできる。
- 既存研究への転用→Veo3のような動画生成AIも同じ技術が転用できるかも→YouTubeのシークバーのようにリアルタイム生成ができる世界線
- NEATや遺伝的アルゴリズムなどを組み合わせたLLM用アーキテクチャの最適化探索→現在のLLMは推論学習評価が何千万と何ヶ月とかかるが、もし学習が一瞬で終わるならば、TransformerやBERTなどのアルゴリズムをNEAT法や遺伝的アルゴリズムのような形で交配させ、新たな高精度なアーキテクチャを自動生成できる可能性がある→AIが自律的に頭が良くなっていく可能性があり、技術的特異点はこの技術の可能性がある
- 精度はある程度で良い
- モデルの仕組み上、多分既存のGPUに比べて尤度を取りにくいので性能落ちる気がする
- 精度より速度求めたい。精度を求めるのは私の専門外。そもそも私はCNNやYOLOを30万FPSで動かすようなことをベースにやってきたので精度は私にとって二の次
- 学習が数百倍から数千倍早くなるかも→推論と学習を早くするのが私の求めている世界
- 推論はほぼ確定で数百倍から数千倍早くなることがわかっている
- 学習に関しては未知数だが、GPUで誤差逆伝播する方法に比べてすべてパラレルで重み調整できたり、仮にエラーを伝播させてもGPUでの誤差逆伝播より早くする
- コスト削減
- 既存の10~1000分の1にハードから電気コストなどを削減できる可能性(理論値測ってないが、モデルの構造上そうなる)→低資源の日本に追い風
解決方法:GPUなど使うな
- 本当は誤差逆伝播など使うなと言いたかったが、ニューロンモデルにおける誤差逆伝播は計算グラフ最適化において生物を凌駕しているかもしれないほど強力的すぎたかもしれない
- 日本がGPU使ったところで限界値は知れているので、GPUで戦ってはいけない
- そもそもニューロンをシリコンに優しく実装すべきで、シリコンに優しくニューロンを実装してしまっている=GPUを使っている状態がダメ
- 何を馬鹿なことを、GAFAMを敵に回すのかと思うかも知れないが、単純に脳がGPU演算なわけがないわけで、国産でやるならもっと違うドメインで勝負してやろうという話
- 別に国に対して言っているわけではなく、これは私の思想で、私自身に対してGPUを使うなと言っている
- 本当は多くのエンジニアが何も考えずにGPUと誤差逆伝播を使っているのは危惧すべき状態だと思うが、それはまた別の機会で
具体的な技術
- あまり公にすると外側に真似されてしまうので、抽象的に書いておくが、研究開発している内容は伝わるはず
- GPUを使わずに専用回路を使う→PoCはFPGAで良い、最大の課題はパラメーター数だが、10万tok/secなら、10回を一つのクロックとして扱って推論 or 学習させる、重み時間軸展開の構想
- 微分可能回路→LGNなどが該当、sigmoid関数でゲートを選択するのではなく、直接学習させるなど→計算数が圧倒的に減る
- 確率演算
- 誤差逆伝播に変わるアルゴリズム開発→エラーが後ろから伝播しないので全ての重みを同時に計算できたりして面白い→つまり誤差逆伝播に比べて数百倍から数千倍学習が早くなる可能性がある(Pythonコードは今年の4月ぐらいにもう完成してしまっている)
- 伝統的なニューラルネットワークの破壊→アミン系やその他ニューロンの構造参考(ED法など)
- 独自フレームワーク開発→もちろん既存のPyTorchやTensorFlowなどは全部動かないのでフレームワーク自作。そもそも誤差逆伝播のためのパースから組み直す
- 独自アーキテクチャ開発→Transformer, BERT, RNNみたいなモデルはそもそも微分可能なニューロンに対して作られて、活性化関数もステップじゃなかったり全く違うものなので、新しい言語モデル用のアーキテクチャも作ることになる→実際、Transformerをベースに作るが、性能が出ないはず
今後の研究開発について
- この研究は国益につながるので、なるべく丁寧に慎重に進めたい
- 進捗は出せる範囲でTwitterで出す
- とはいえこの研究は日本国から出資があるわけでもなく、東大生でもなければ人脈もないので、お金の面で苦労するのは事実
- 現在関わっているプロジェクトが複数ある&開発チームが生きていくために他のプロジェクトで稼ぐ必要があるため、最大のボトルネックはそこになるはず
- 資本問題
- 一番のルートはIPAのアドバンスド事業 or 関係者連絡
お問い合わせ
Q&A
全部は拾えないですが、おおまかに回答させていただきます。ありがとうございます。
- チューニングではなく作るのでしょうか?
- チューニングが楽ですが、結局ニューロン構造もエラー伝播の仕方も全く違うので0→1になりそうですが、既存のモデルから我々のモデルに変換するコンバーターを作ってみる価値はありそうです
- 失敗する未来しかないね
- 成功が低確率+別に東大生などではないので多分そう思われるのは正しいのですが、ある程度動くコンポーネントがあるのでくっつけたら動きそうではあります。確率は0ではないので単純にやってみるだけです。こんな狂ったこと、我々以外やらないと思いますので。
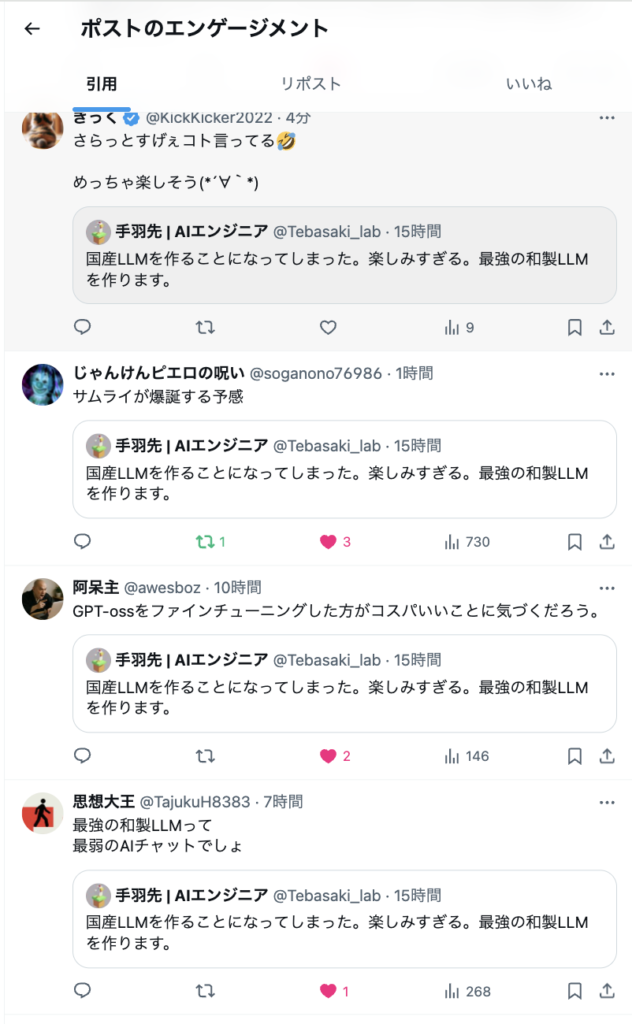
- 最強の和製LLMって 最弱のAIチャットでしょ
- 精度で言えばその可能性は十分にあります。何せまだモデルができておらず精度判定すらできていないので、低精度になる可能性は大いにあります。ただ、現在のBERTぐらいの精度のものが10万tok/sで動けば、Aniみたいなものであったり、日本国におけるアニメキャラと0秒で会話できるので、その展開も十分に強いかと思います。
- GPT-ossをファインチューニングした方がコスパいいことに気づくだろう。
- 基本そうです。ただ、そのようなレールに乗っていては、つまりGPU、誤差逆伝播、現在のニューロンモデルでは演算速度に限界があります。精度、すぐに動くものはそちらの方が良いです。我々が目指しているのは、全く新たなLLMです。
- データセットはどうやって集める予定ですか?
- 特に私ですが、CNN, YOLO周りの高速化から入った人間なので(そもそもそれが目的でした)、LLMは実験中という形です。基本的にまずは動くかどうかの検証、PoCが最優先なので、BERTの日本語モデルに使われているもの、超ミニマムなWord2vecを作ってみるところから始めようとは思っています。まずは0→1達成に時間を割くべきで、動く、学習するほど精度が上がるならばデータセットを考えます。その頃には何かしらの機関と協力関係にあるかも知れません。
- CPUオンリーでお願いします
- そもそもCPUやGPUの概念を超えているので互換性はないです
最後に
強い発言があったかも知れませんが、炎上目的でもなんでもなく、私の思想です。これぐらい狂ってないと誤差逆伝播法や世界には勝てないとは思っている人間です。否定的な意見、肯定的な意見、我々に興味を持っていただいたことに全てに心の奥底から感謝させていただいております。ありがとうございます。
研究とは失敗するもの、こんなもの失敗に終わるだろうとは思う、思われるものですが、もし成功すれば日本、世界がぶち上がるんではないかと思います。とりあえず、やらない後悔よりやって後悔したいので、若手のエネルギーを使ってやれるところまでやってみます。やれば上手くいかない仕組みが砂金として残るので、意味はあります。

コメント