



はじめに
ちょうど一ヶ月前、国産LLMを作ると宣言したところ大きな話題になりました。あれから1ヶ月の進捗と今後の進め方、新アルゴリズム発見について書いていきます。
前提
国産LLMを作るに至った背景は以下をご覧ください。

- 私は開発者であり、研究者ではありません
- 個人のお金で研究開発しています
- フルタイムで働いた後に夜中から朝5時まで開発する生活を先月から今日までやっています
- 先行研究などを出せと言われたので、下の方に貼っております
- 学習アルゴリズムの仕組みについては下の方に書いておきます
1ヶ月の成果のまとめ
- 今まで見つかっていない新しい学習アルゴリズムを発見
- BP無し、重みを並列計算可能、微分無し
- MNIST精度90%超え
- FPGA上で推論動作実験済み!!
- →1クロックで1層→50Mhz~500Mhzで動作可能
- clk: 50MHz 周期でいうと20ns
- 精度96.0% (1000枚中960枚正解)
- 自然言語処理、LLMに向けた基盤ができ始めた
- 独自のフレームワーク, MDZeroを開発中
具体的な成果
新学習アルゴリズムの発見
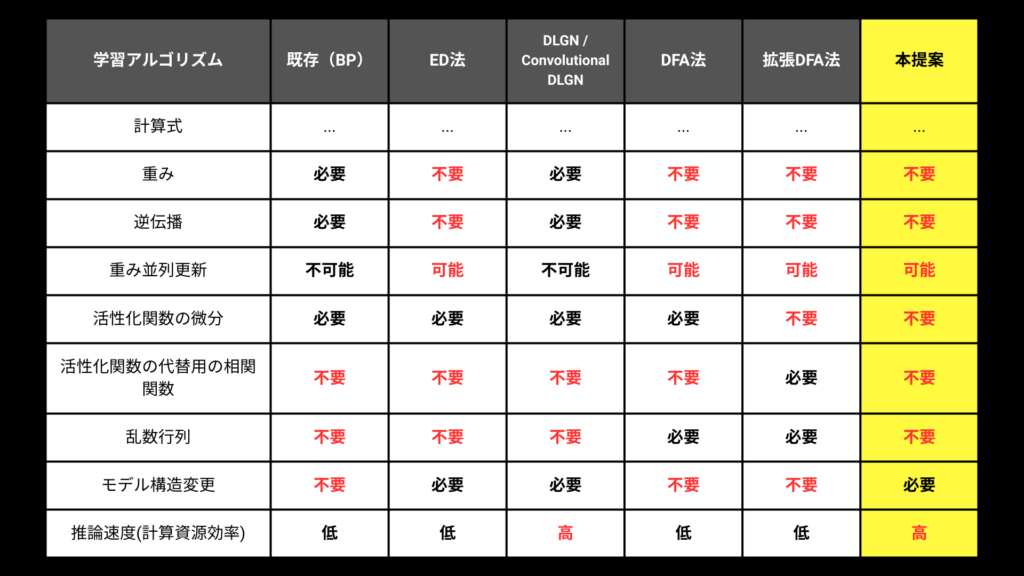
開発チームは、既存のBack Propagation(誤差逆伝播法)に変わる新しいアルゴリズムを発見しました。BPに変わる、もしくは近い学習アルゴリズムの研究は多く存在し、その中でも有名なアルゴリズムと比較した表が画像です。以下の特徴があります。
- 100万,1000万パラメーターあろうが同時に重みを計算、更新可能
- 層を100層に増やしても学習する
- 勾配消失がない
- 計算時に今まで必要だった以下のパラメーターが不要に
- 重み, 活性化関数の微分, 相関関数, 乱数行列, 微分
- 1層1クロックで動くアーキテクチャに直接変換可能
- 考え
- 微分を使っていないので、Stochastic Computingを入れても動く可能性がある
- つまり、FPGA上でバイナリで学習できる可能性もあり
- 微分を使っていないので、Stochastic Computingを入れても動く可能性がある
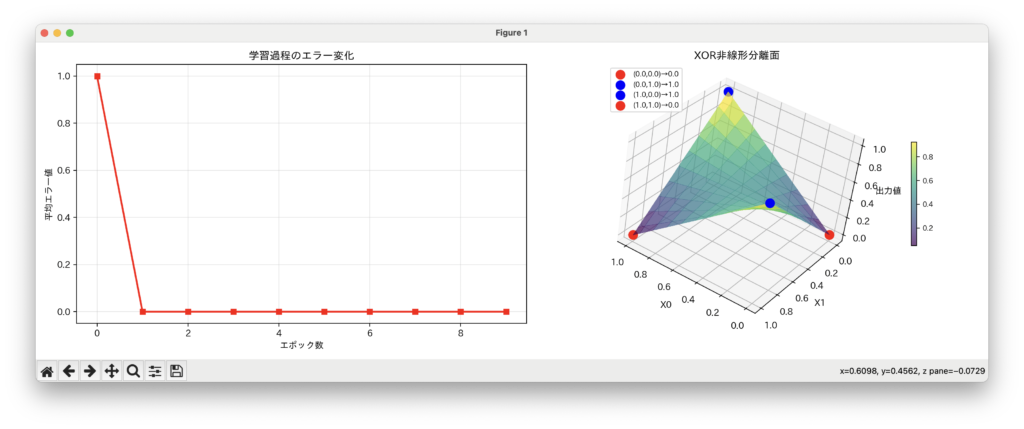
類似研究は山のようにありますが、全て微分や重みなどを使っているので、私がやっているのとは別になります。関連論文は記事の下に貼っておきます。
また、なぜ学習が進むかは開発者本人である私も分かっていません。単体ニューロンでXORや任意のゲートおよび関数を学習できるようにアルゴリズムを作ったところ、3層でも100層でも256層でも学習してしまった、というのが現時点で分かっていることです。
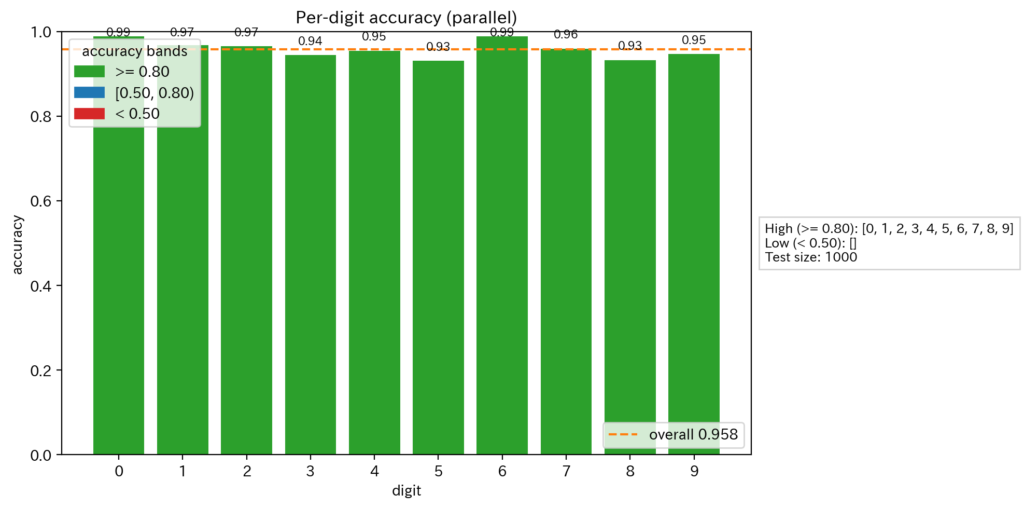
MNIST精度90%超え
MNISTという手描き文字を認識するタスクがあり、私たちが作ったニューロンと学習アルゴリズムは90%を超える精度を出すことに成功しました。他のCNNやBPに比べて精度は劣りますが、半月前に発見されたアルゴリズムを入れてみたら動いてしまったので、まだまだ精度向上の可能性と高速化の可能性を秘めています。
スケーリング則が適用されることを確認
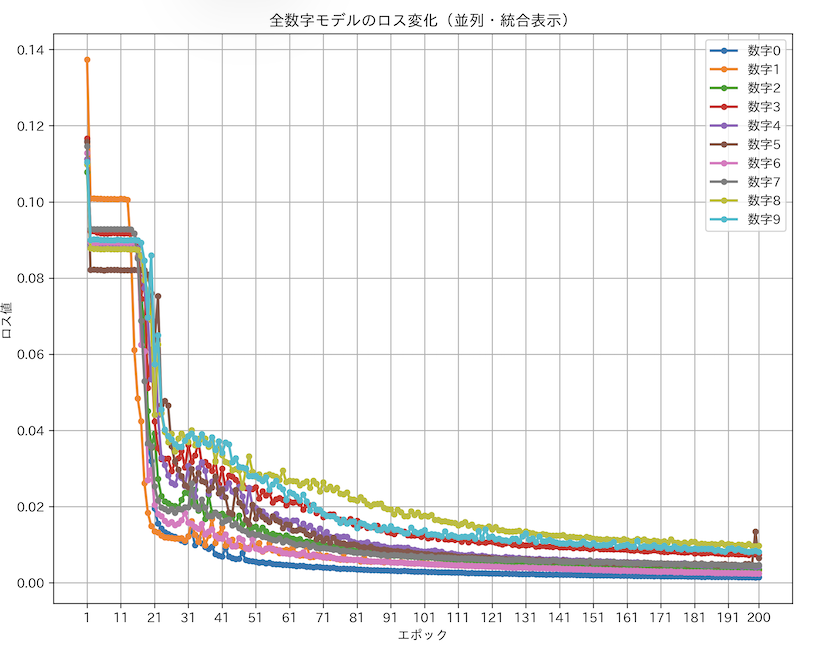

64サイズの中間層を100層用意してMNISTを学習させたところなんと学習し、精度も過去最高になってしまいました。つまり勾配消失はないですし、モデルをでかくすればするほど性能が上がることが分かりました。今回のモデルでは117万パラメーターを使っており、このパラメーターがどんどん増えると性能が上がるということです。MNISTごときに100万パラメーターかと思うかもしれませんが、モデルの構造上、現時点では重みを共有できていなかったり、1出力につき1モデル必要になっているため、10倍のパラメーターが必要になります。最大の欠点でもありますが、初期段階では1つのモデルで学習成功していたり、重み共有やモデル構造の改良はいくらでもやりようがあるので、まずはスケーリング即が適用されることを確認しました。
※これの凄さは、でかくすればするほど性能が上がり、100層重ねても勾配消失がなく、114万パラメーターが並列で同時に更新されているという事実です。BPではあり得ません。

秒間5億枚処理可能

とはいえ、推論であればTAIの中原さんやLUT-Networkの渕上さんが既にされているので、強調したいのは、新しい学習アルゴリズムで同等の推論速度が出せるということです。
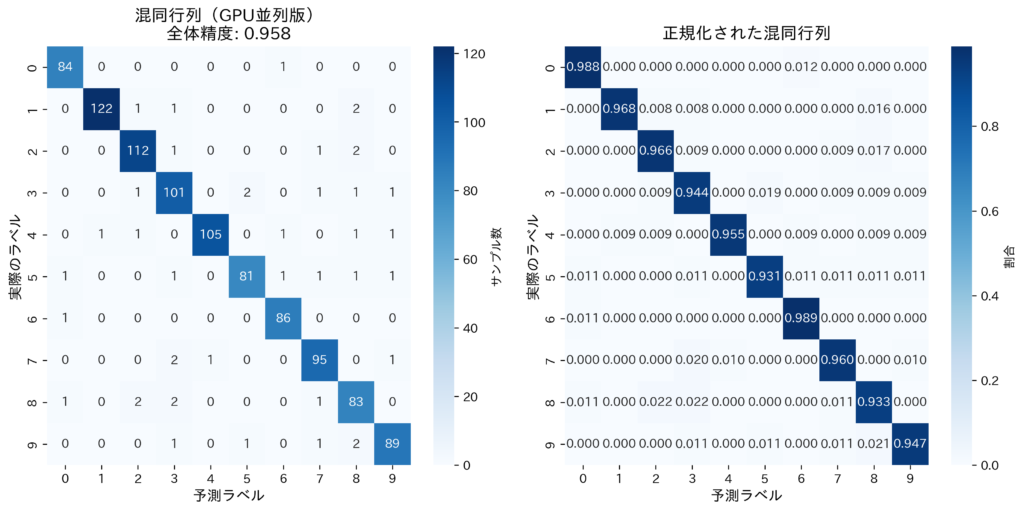
FPGA実機でのテスト
これはとんでもないことなのですが、開発チームの1人であるN氏が、記事の前日にFPGAに私のニューロンの専用回路を開発し、実機での検証が可能になりました。256枚中205枚分類に成功しているので、ランダムで動いている訳ではなさそうです。1000枚中960正解しているので、96%達成しているようです。(2025/09/24)
とはいえ、GPU上で学習、シミュレーションしたニューロンをFPGA上で動くようにコンパイルする際に尤度が失われてしまうので、MNISTの精度が20~30%程度低下するという大きなデメリットを抱えています。しかし、GPU上での学習を改良すれば解決できる問題なので今後開発を進めていきます。

また、宣言ツイートをした一ヶ月前から知り合ったM氏(FPGA, DFA)も率いて開発を進めてまいります。
今後について
- NN以外のアーキテクチャ開発
- 現在、全結合層しかできていないので、CNN,RNNなどに応用していきます
- LLMの開発
- 現在は画像認識タスクなので、来月からはLLMに近づくため自然言語処理に取り掛かります。
- 具体的にはCBOWやAttention,RNNなどです
- 技術の公開について
- このアルゴリズムが見つかったこと自体が半月前ですので、安全かつ丁寧に公開準備を進めていきます
- 未踏ITや起業、企業との共同研究など、色々と進めております
まとめ
LLMを作ることは可能なのでしょうか?ー否定はできません。
質疑応答
- ただのOCR?LLMはどこに?
- ニューロンとその学習アルゴリズムが作っているので、まずは有名なMNISTからやりました
- ここからCBOWなど、言語系のアーキテクチャを開発していきます
- なぜBPや既存NNを使わないのですか?
- どうやってAI勉強しましたか?
- ゼロつくと論文漁りです
- どうやってこのアルゴリズムを思いついたのですか?
- 夢の中で東雲なのが教えてくれました
- 早く論文出して
- 論文を出すと仕組みが全世界に公開され、せっかくの技術が違う国にパクられて国や組織として不利益になります
- →なので特許があります
- じゃあ早く特許出して
- 国ごとに取る必要があったり、莫大なお金がかかるため、検討中です
- 公には出せませんが、某企業や組織との連携も進めているため、お待ちください
- 精度悪いからこの手法は意味ないのでは?
関連研究




https://patentimages.storage.googleapis.com/45/46/00/ba40865a7fa961/EP3816873A1.pdf
https://www.i.u-tokyo.ac.jp/news/files/ist_pressrelease_20230110_nakajima.pdf
- 以下、LUT関連

Deep Differentiable Logic Gate Networks — https://arxiv.org/abs/2210.08277 arXiv
Convolutional Differentiable Logic Gate Networks — https://arxiv.org/abs/2411.04732 arXiv
Convolutional Differentiable Logic Gate Networks (NeurIPS 2024 proceedings版) — https://proceedings.neurips.cc/paper_files/paper/2024/file/db988b089d8d97d0f159c15ed0be6a71-Paper-Conference.pdf NeurIPS Proceedings
Truth Table Net: Scalable, Compact & Verifiable Neural Networks — https://www.ijcai.org/proceedings/2024/0002.pdf ijcai.org
Differentiable Weightless Neural Networks — https://arxiv.org/abs/2410.11112 arXiv
LogicNets: Co-Designed Neural Networks and Circuits for Extreme-Throughput Applications — https://arxiv.org/abs/2004.03021 arXiv
LUTNet: Rethinking Inference in FPGA Soft Logic — https://arxiv.org/abs/1904.00938 arXiv
LUT-NN: Empower Efficient Neural Network Inference with Centroid Learning and Table Lookup — https://arxiv.org/abs/2302.03213 arXiv
PolyLUT: Learning Piecewise Polynomials for Ultra-Low Latency FPGA LUT-based Inference — https://arxiv.org/abs/2309.02334 arXiv
PolyLUT-Add: FPGA-based LUT Inference with Wide Inputs — https://arxiv.org/abs/2406.04910 arXiv
NeuraLUT-Assemble: Hardware-aware Assembling of Sub-Neural Networks for Efficient LUT Inference — https://arxiv.org/abs/2504.00592 arXiv
PoET-BiN: Power Efficient Tiny Binary Neurons — https://arxiv.org/abs/2002.09794 arXiv
TreeLUT: An Efficient Alternative to Deep Neural Networks for Inference Acceleration Using Gradient Boosted Decision Trees — https://arxiv.org/abs/2501.01511 arXiv
Scaling Up LUT-based Neural Networks with AmigoLUT — https://dl.acm.org/doi/10.1145/3706628.3708874 ACM Digital Library
A Survey on LUT-based Deep Neural Networks Implemented in FPGAs — https://arxiv.org/abs/2506.07367 arXiv
新しい学習アルゴリズムの仕組みについて(一部)
全てを公開するとアレなので、一部だけご紹介します。
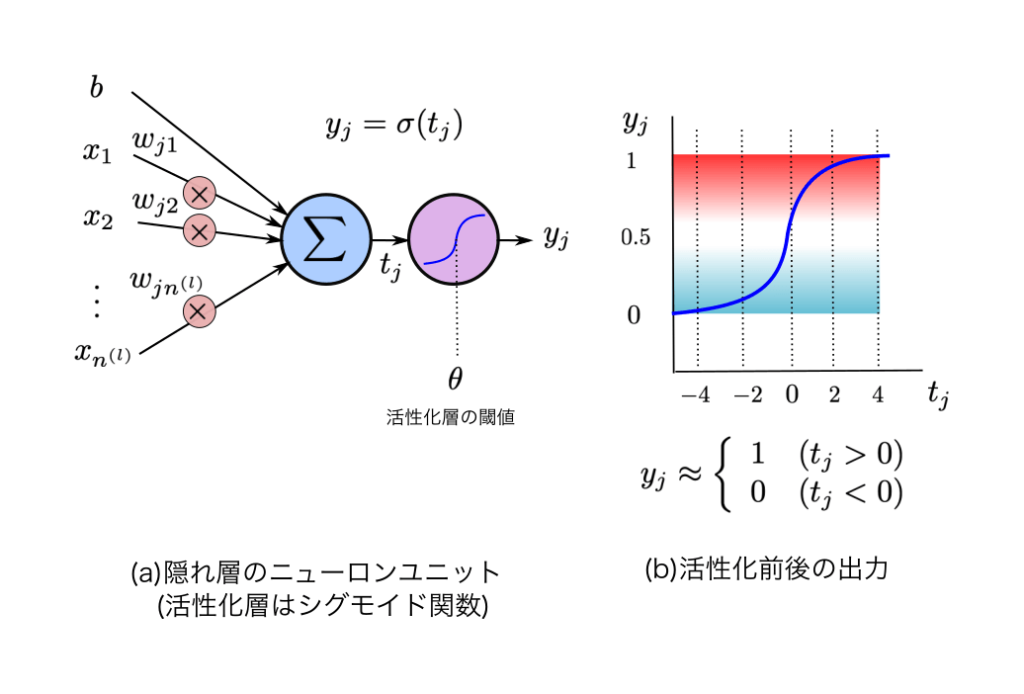
画像のように、今までの学習方法とは色々と違います。最大の特徴として、
- 微分不使用
- 活性化関数の位置の逆転
- 学習時に必要なパラメーターの大幅削減
この二つが大きいです。
微分を使っていないため、複雑な計算式がいりません。また、計算量が圧倒的に減ります。
活性化関数の位置の逆転というのは、今までのニューロンは積和結果を活性化関数に入れ、それを0~1に正規化及び非線形に変形していました。私のニューロンは、その位置関係を逆転させました。つまり、入力は活性化関数→積和演算となります。そんなので動く訳ないと思っていたのですが、依存関係を逆転させることによって微分も複雑な計算も、パラメーターも減りました。
事実、私の学習アルゴリズムは「エラー率」「前回の入力値」「学習率」だけで重みを更新できます。
しかもニューロンは前後の位置をなんとなく把握できるようにモデルの構造を工夫しています。

コメント
重みの適用と非線形の活性化関数の適用の順番を入れ替えるのは興味深いですね。解析学的にどう評価されるかが気になります。
すみません、返信遅れました。正確に言えば活性化関数の役割は後ろ側も担ってはいるのですが、そこには活性関数を通していない単純な計算のみ使っているため、微分がいらなくなった、という表現が正しいかったと今は思います。解析学的にどのようになるかはまだ未知数ですので、チームメンバーと共に開発および調査を進めて参ります。
活性化関数の位置の逆転についてですが、2層以上の場合にこの効果って逆転前と同じになりませんか?
すみません、返信遅れました。この質問もよくいただくのですが、確かに逆転前と同じには部分的にはなるのですが、このニューロンは誤差逆伝播と違ってニューロンごとに局所的かつ並列に学習しますので、ニューロンの中の活性関数の位置および適用部分が重要になり、レイヤー全体としての位置はあまり関係ない構成になっております。なので、2層以上の場合であっても、レイヤー全体で見れば順番はあるところから一緒になりますが、ニューロン単体の中身をのぞいてみると局所的に学習する際には位置関係が逆転している=それで学習が成功してしまう、という構造になっております。
返信遅れましてすみません。こちらの質問、よくいただくのですが、確かに逆転前と同じには部分的にはなるのですが、このニューロンは誤差逆伝播と違ってニューロンごとに局所的かつ並列に学習しますので、ニューロンの中の活性関数の位置および適用部分が重要になり、レイヤー全体としての位置はあまり関係ない構成になっております。なので、2層以上の場合であっても、レイヤー全体で見れば順番はあるところから一緒になりますが、ニューロン単体の中身をのぞいてみると局所的に学習する際には位置関係が逆転している=それで学習が成功してしまう、という構造になっております。